こんにちは。NFLabs. 事業推進部の野中です。
本記事はNFLabs. アドベントカレンダー 6日目の記事です。
平時はセキュリティ技術について記載することの多い本ブログですが、今回は視点を変えてネットワーク運用の観点からのお話をしたいと思います。
運用そのものについて語ると相当長くなってしまいそうなので、本記事では監視運用の中でもメジャーなトピックであり、なおかつ考慮し忘れてしまうことも多い「497日問題」にスポットを当ててご紹介します。
497日問題とは
簡単に言うと、システム稼働時間を32bitカウンターで計測している場合、497日でオーバーフローしてしまうという問題です。
32bitで扱える数値は、unsignedの場合 2の32乗 = 4294967295 が上限です。
システム稼働時間(uptime)は10ミリ秒単位で計測するものが多く、上記の上限値に当てはめると約42949673秒 ≒ 約497日2時間28分 となります。
したがって、32bitカウンターを使用しているシステムは497日までしかuptimeをカウントできず、それを超えるとオーバーフローして0に戻ってしまいます。
なんだか2000年問題を思い出しますね。
これは32bitの機能上の制約に基づく事象なので、不具合ではなく仕様として捉えられます。
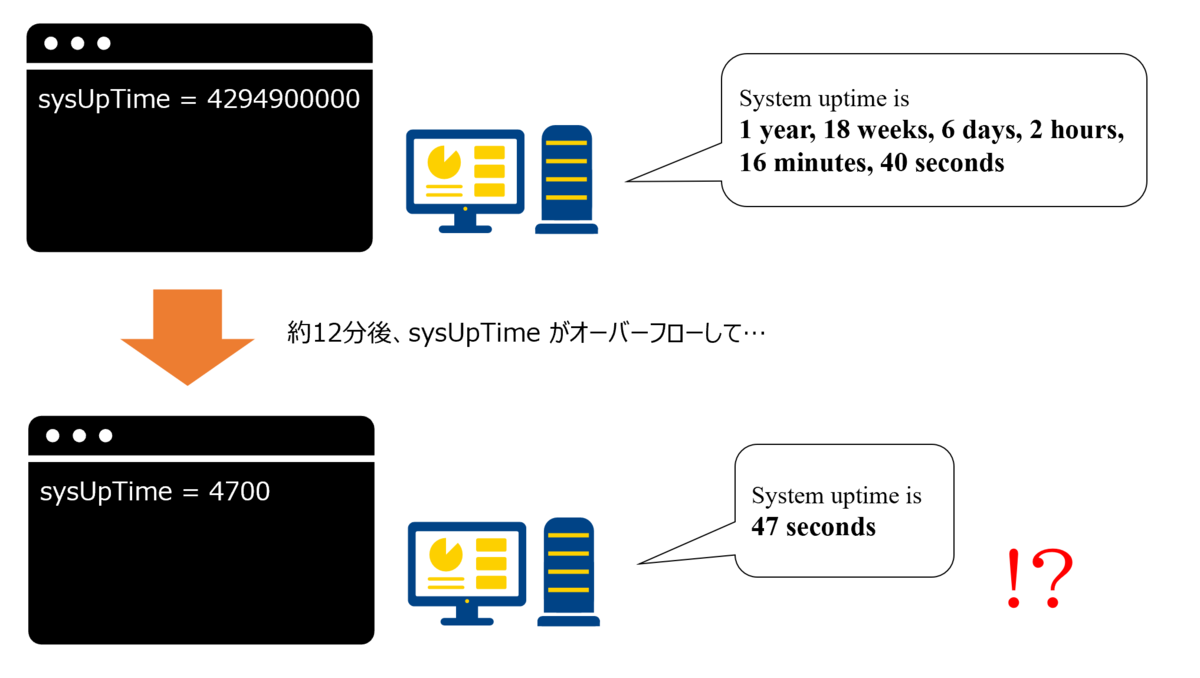
図1: 497日問題によるuptimeオーバーフローのイメージ
この事象の直接的な影響としては、uptimeのカウンターが0に戻ってしまうことにより正確な稼働時間が取得できなくなることです。
497日というと1年と4ヶ月強なので、そんな昔に遡って起動時間を確認したい理由はそれほど無いようにも感じられますが、サーバやネットワーク機器などはトラブルが起きていなければ数年間停止せずに稼働し続けていることも珍しくないので、むしろ安定的なシステムほどこの事象の影響を受けやすくなります。
古いバージョンのOSだと497日問題の対象になってしまうことがあり、稼働時間のリセットだけでなく、uptimeを参照するあらゆる処理やTCP通信ができなくなるなどの事象が確認されています。
Windowsにおいても、Windows 7やWindows Server 2008などの古いバージョンのOSは497日問題の対象となっており、Microsoftから修正パッチやワークアラウンドが公式にアナウンスされています。
ちなみに497日問題の亜種として、以下のような問題もあります。
- 248日問題:32bit signedの場合は扱える数値が2147483647までとなるため、497日の半分である約248日13時間14分でオーバーフローしてしまう
- 49.7日問題:32bit unsignedの数値上限をミリ秒でカウントすると497日の10倍早くオーバーフローしてしまう
- 2038年問題:UNIX時間(UTC 1970/01/01 00:00:00 からの経過秒数で現在時刻を算出)において32bit符号付整数の秒数カウンターを使用している場合、2038/01/19 03:14:07 を過ぎると経過秒数が負の値を取ってしまい、正常な時刻が表示できなくなる
監視業務への影響
システムの監視をする際はSNMPを通じて様々な情報を収集することが多いですが、システムが起動してからの経過時間を表す標準MIBであるsysUpTimeは32bitカウンターであるため、がっつり497日問題の対象となります。
一方で、497日問題にあたるとしても、サーバやネットワーク機器における実質的な影響は稼働時間がオーバーフローしてしまうという点のみです。
これだけ聞くと、あれ?そんなに大したことないんじゃね?と思われるかもしれません。
しかし、対象となる機器を監視している場合、特に24時間365日の監視運用を導入している環境の場合は、事の重大さは全く異なってきます。
ほとんどの場合の監視業務において、uptimeが0になるということはシステムが再起動したということを意味します。
機器の電源断は大抵の場合Pingによる死活監視によって検知できますが、瞬間的な停電などによりごく短時間の電源断にとどまり、その後すぐに再起動・通信復旧すると、Pingのポーリング間隔によっては検知できないことがあります。
そのような場合でも、「機器の電源断および再起動が発生した」ことを確実に検知するため、Pingでの死活監視に加えsysUpTimeの値を監視項目として採用し、これが一定の値以下(よくあるのが10分未満)になるとアラートを発出するような監視設計になっていることが多いです。
短時間とはいえ「電源断があった」という情報一つ取ってみても、例えば、
- 対象機器が止めてはならない通信やサービスに関係している場合、商用環境への影響が発生
- 機器に搭載されているOSのバグにより、予期せぬ再起動が発生した
- 機器が接続されている電源やUPSに不具合が生じており、電力供給が不安定になっている
などなど、想定される影響やアラート発出の原因、またそれを受けた原因究明や再発防止に向けて考慮しなければならない要素は数多く存在します。
そのため、基本的にsysUpTimeのアラートは重要度が高く設定され、検知時には早急な対応が求められます。
さて、そこで497日問題です。
これが発生すると当然sysUpTimeアラートが発出されるわけですが、その原因は前述の通り32bitカウンターのオーバーフローなので、実際に機器が再起動したわけではありません。つまり誤報が飛ぶことになります。
前述したようにこのアラートは重要度が高く設定されることが多いため、検知後すぐに担当者にエスカレーションされるわけですが、こと24時間365日の監視体制の場合、たとえ土日祝日の憩いの中でも、ぐっすり眠っている夜中であっても、アラートが鳴ればお構いなしにエスカレを受け、復旧対応に駆り出されることとなります。
体制や契約によってはこのタイミングでお客様へも一報を入れ、状況説明や以降の定期的な進捗報告などを行う場合もあるかもしれません。
そしてありとあらゆる被疑箇所を調査しまくった結果、電源断など発生していないことが判明し、「誤報でした。テヘ☆」という何とも無念な結末が待っているわけです…。
497日問題による運用上の影響というのはまさしくここにあります。32bitカウンターを使っている限り、sysUpTimeのオーバーフローに起因する誤報を検知するたびに、本来する必要のなかった運用対応稼働が発生してしまうという悩みと常に付き合っていかなければなりません。
運用対処
となると当然、497日問題を起因とする誤報対策が必要となってきます。
ざっと思いつく限りでは、497日問題の対処として大きく以下の3つが考えられます。
- 64bitカウンターを使用する
- 監視システム側でアラートの発出条件を変更する
- 他の関連アラートと同時に検知した場合のみ対応するよう、運用フローを調整する
1. 64bitカウンターを使用する
これができるのであればこの方法で対処するのが一番手っ取り早いです。32bitで足りないなら64bitにすればいいじゃない!ということですね。
64bitだと扱える数字が一気に 18446744073709551615(5億年ボタンを1回押しても耐えられる)まで増加するので、497日問題に根本から対処できます。
SNMPでuptimeを取得する場合、標準MIBだと32bitカウンターが使用されるため、各ベンダーそれぞれが独自に定めている拡張MIBを使うことになります。
拡張MIBはどの機器でも初期状態で使えるものではなく、一定のOSバージョンや機種にしか入っていなかったり、公式サイトからダウンロードする必要があったり、機器自体がインターネットから取得しなければならなかったりと、何らかの手段で対象機器において使えるようにする必要があります。
Ciscoの機器の場合、一部の機種は最初から拡張MIBであるcseSysUpTimeが使用可能となっています。MIBファイルも公式サイトで公開されています。
www.cisco.com
Juniperの場合は、JUNOScriptという独自のスクリプト言語を用いて、64bitのMIBを設定するという対処方法がアナウンスされています。
kb.juniper.net
一方で、機器やそのベンダーによってはそもそも64bitカウンターが使えなかったり、インターネット接続が制限されている環境でMIBがダウンロードできなかったりと、どうしても32bitのカウンターを使わざるを得ない場合があります。
その時は後述の2および3の方法を用いて、監視システム側の設定やフローの調整によって何とかアラートの発出を抑える / アラートが出ても誤報と判断できれば対応せずにクローズする仕組みを作るという、いわば創意工夫を凝らした「運用対処」を実施することとなります。
ここが運用担当の腕の見せ所です。
2. 監視システム側でアラートの発出条件を変更する
使用している監視システムによっては各アラートが発出される条件を変更することができるため、それによって497日問題と推定される場合はアラートを発出しないように調整するという対処方法です。
64bitカウンターが使えない場合は497日でのuptimeのリセットは避けられないため、それなら監視側の設定変更でどうにか対処しようということです。
例えばZabbixを使用している場合、独自の記法によってアラート条件式をかなり詳細に設定することができるので、環境や条件に合わせて作り込めばアラート検知の精度をより高めることができます。
下記の設定例ではuptime関連のアラート条件を、単純にsysUpTimeが10分を切っただけでなく、それに加えて直近10分の間にsysUpTimeがオーバーフロー寸前レベルの高い値を取っていなかった場合のみアラートを発出する設定としています。
{HOSTNAME:system.uptime[sysUpTime].last()}<10m
and {HOSTNAME:system.uptime[sysUpTime].max(600)}<42949073
これでもまだ完璧ではありませんが、このようなちょっとしたトリガー変更でも497日問題によるアラート発出は大幅に抑えることができます。
3. 他の関連アラートと同時に検知した場合のみ対応するよう、運用フローを調整する
前述の1・2と比較すると状況は限定的ですが、アラート検知時の一次対応者(以降、本記事では監視担当と呼びます)が別途存在する場合、アラートの出方から497日問題と断定できる時はお客様への通知や運用担当へのエスカレをしないようなフローを設定することで対処できます。
特に24時間365日の運用体制で、監視業務部分をサービスとして他組織に委託している場合などは、自組織の運用担当とは別に他組織からの監視担当が存在することとなります。
例えばsysUpTimeのアラート検知時、それがもし本当に機器の再起動に起因するものであったとしたら、監視システムからのPing疎通不可や接続対向側機器のポートDownなど、対象機器への通信断が発生したことを示す他のアラートがsysUpTimeのアラートより前に検知されていると考えられます。
そのようなアラートの関連性や順序性をもとに、本当に対応すべきアラートのみをうまく掬い上げられるように、監視担当におけるフローを変更・調整していきます。

図2. 497日問題に対応した運用フローの例
図2の例では、重要度:高 に相当するsysUpTime関連アラートを検知した場合でも、同時刻~その少し前に同機器に関するPing疎通アラートを検知した形跡が無ければ、実際に当該機器での再起動は起こっていない(= 497日問題による誤報)と判断し、お客様への通知および運用担当へのエスカレを実施せず、そのまま回復したらクローズとするようなフローとなっています。
運用フローは技術的な制限などが無いため、監視担当との調整次第で詳細なフロー策定ができ、それによって497日問題以外の問題にも対応できる可能性もあります。
ただし、フローがあまりに複雑になりすぎると今度は監視担当の稼働が増えてしまい、監視業務に支障が出てしまうこともあるため、そのあたりを監視担当に事前によく相談したうえでフローを策定していくとよいでしょう。
まとめ
今回の記事ではネットワーク運用にスポットを当て、その一例として497日問題の紹介と運用における対処方法についてご紹介しました。
今回特に皆さんにお伝えしたかったことは、運用は奥が深くて面白い!ということです。
技術的な手法ではどうしても根本解決できない問題が生じたとき、いかに視点を変えて別の角度からの解決策を見つけられるか、いかに持ち合わせの知見で対処できるかという、論理の組み立てや問題解決力が求められます。
いうなれば、自身のアイデアをパズルのピースに見立てて、解決すべき課題に対してはめていくような感覚です。これがぴったりはまった時ほど気持ち良いことはありません。
運用 = 運用対処 というわけではなく、しばしば監視業務を内包していることもありますが、運用対処の考え方自体は広く様々な場面で役に立つものだと思っています。
皆さんももしこれを機に運用に興味を持っていただけたら、もっと運用チームのことを崇めてください後々の運用のことを少しだけ意識して開発・構築をやってみたりするのもよいかもしれません。