概要
- SECCON 13 CTF 国内決勝で Team Enu は 9 チーム中 7 位の成績を収めました。
- 本記事では simple_reversing 問題と Allegro 問題を解説します。
はじめに
こんにちは、研究開発部の末廣です。 SECCON 131 で開催された CTF イベントの SECCON 13 CTF 国内決勝2に、 NTT グループ有志のチーム Team Enu3 で参加しました。結果、 9 チーム中 7 位の成績を収めました。
当社とNTTセキュリティ・ジャパンのメンバーによる Team Enu が #SECCON 13 CTF 国内決勝で7位を獲得しました。
— エヌ・エフ・ラボラトリーズ (@NFLaboratories) 2025年3月4日
応援してくださったみなさん、および素晴らしい大会を開催してくれた運営のみなさんに感謝いたします。 pic.twitter.com/bTlu5FCrIQ
なお、予選時のブログ記事も執筆しております。ご興味があればそちらもご覧ください。
筆者は Jeopardy 形式 reversing ジャンルの simple_reversing 問題と、 KotH 形式の Allegro 問題へ主に取り組みました。 Writeup として、本記事ではそれらの問題を解説します。
問題の出題形式
決勝では、 Jeopardy 形式の問題が Welcome 問題含めて 19 問、 King of the Hill 形式の問題が 2 問出題されました。本コンテストでの 2 つの出題形式は次の特徴を持ちます。
- Jeopardy 形式:
- オンライン開催の CTF 等でよく出題される形式です。
- 各種問題からフラグを見つけて回答します。
- フラグを提出したタイミングで得点が得られます。
- コンテスト開始早々に正解しても、コンテスト終了間際に正解しても、得られる得点は同一です。
- 他チームが関連する要素は、「多くのチームが解いた問題ほど得点は低くなる」と間接的です。
- King of the Hill 形式 (略称 KotH):
- 少数のチームが一堂に会する場合に出題される形式の印象です。
- チーム間で直接競争します。
- 1 ラウンド 5 分 ごとに得点が得られます。
- そのためコンテスト開始時から高順位を取り続けると高得点に繋がります。
- 一方で、コンテスト終了間際にのみ高い順位を取っても得点への影響は少ないです。
決勝全体の順位は Jeopardy 形式と King of the Hill 形式それぞれの合計点数で決定されます。
simple_reversing
Jeopardy 形式の reversing ジャンルの問題で、 amd64 ELF バイナリのフラグチェッカー問題です。実行すると文字列を入力でき、入力した文字列がフラグと一致するかどうかを出力する機能を持ちます。
バイナリそのものは、 glibc が動的リンクされているにもかかわらず、ファイルサイズが 1.2MiB ほどある大きい内容です。バイナリに含まれる文字列を確認すると、mruby 3.3.0 (2024-02-14) が存在したため、 mruby を静的リンクしているらしいことが分かりました。バージョン 3.3.0 は本コンテスト当日における最新バージョンです。一方でバイナリからはシンボル情報が削除されているため、 mruby のライブラリ関数がどの程度使われているかが不確かな状況でした。
mruby 3.3.04 のソースコードをダウンロードして比較することで、本問題のバイナリのどこまでが mruby のライブラリコードなのか、どこからがバイナリのアプリケーション固有部分なのかを検証していきました。可能性として、「バイナリ中で ruby ソースコードを復号して実行」等があり、バイナリ全体を正確に追跡することが求められる場合を考慮していました。
比較した結果、バイナリの大部分は mruby のライブラリコードであり、バイナリ固有のアプリケーションコード部分はごく少量であることが判明しました。解析初期から怪しいと思っていた case 'PERI' や case 'GBD', case 'RAVL' や case 'DNE' といった分岐も、それぞれ mruby の read_irep 関数で使われている RITE_SECTION_IREP_IDENT, RITE_SECTION_DEBUG_IDENT, RITE_SECTION_LV_IDENT, RITE_BINARY_EOF シンボルに対応する分岐と分かりました。
なお本記事を書いている今となっては、手元で mruby をビルドして IDA のシグネチャ作成ツールでシグネチャを自作し、 mruby ライブラリ関数箇所を特定すればより効率的に解析できたのではと感じています。
バイナリ固有のアプリケーションコード部分は次の内容です。
int main() { mrb_stakaいte *mrb; // rax MAPDST __m128 *ruby_input; // r12 uint32_t sym; // eax char input[264]; // [rsp+0h] [rbp-128h] BYREF unsigned __int64 canary; // [rsp+108h] [rbp-20h] canary = __readfsqword(0x28u); puts("Input flag:"); if ( !fgets(input, 256, stdin) || (mrb = mrb_open()) == 0LL ) PrintUnknownErrorAndExit(); ruby_input = mrb_str_new_cstr(mrb, input); sym = mrb_intern(mrb, "$input", 6uLL); mrb_gv_set(mrb, sym, (__int64)ruby_input); // グローバル変数の設定 Application_ReadIrepAndExecute(mrb, "RITE0300"); mrb_close(mrb); return 0; } // バイトコードを読み込んで、実行する模様 __int64 __fastcall Application_ReadIrepAndExecute(mrb_state *mrb, const uint8_t *bin) { void *proc; // r12 __int64 result; // rax __int64 top_self; // rax __m128 *v5; // r12 uint32_t v6; // eax unsigned __int64 id; // rax __m128 *v8; // rax proc = MayBe_read_irep( // 「mrb_proc_read_irep」のインライン関数? mrb, bin, 0xFFFFFFFFuLL, (unsigned __int64)bin <= 0xC6895 || bin >= (const uint8_t *)g_maybe_edata_or_etext); result = 20LL; if ( proc ) // 「load_irep」のインライン展開? { if ( *((_QWORD *)proc + 3) ) { *(_QWORD *)proc = 0LL; top_self = mrb_top_self(mrb); return mrb_top_run(mrb, (__int64)proc, top_self, 0LL); } else { v5 = str_new_static(mrb, (unsigned __int64 *)"irep load error", 15LL); v6 = mrb_intern_static(mrb, "ScriptError", 0xBuLL); id = mrb_exc_get_id((__int64)mrb, v6); v8 = mrb_exc_new_str(mrb, id, (__int64)v5); mrb_exc_set(mrb, (__int64)v8); return 0LL; } } return result; }
すなわち、フラグ判定処理は mruby バイトコード部分に存在することが分かりました。上記のアプリケーションコード部分では "RITE0300" として登場しています。しかしヌル文字終端の文字列だけではなく、実際はその後にデータが続いています。
次のステップは mruby バイトコードのリバーシングです。 mruby バイトコードの可視化方法を調査して、最終的に mruby -vb dumped.mrb で逆アセンブルに成功しました。
mruby 3.3.0 (2024-02-14)
irep 0x55b61e516c80 nregs=10 nlocals=4 pools=2 syms=6 reps=9 ilen=94
local variable names:
R1:size_check
R2:split
R3:checker
000 LAMBDA R1 I[0]
003 LAMBDA R2 I[1]
006 LAMBDA R4 I[2]
009 LAMBDA R5 I[3]
012 LAMBDA R6 I[4]
015 LAMBDA R7 I[5]
018 LAMBDA R8 I[6]
021 LAMBDA R9 I[7]
024 ARRAY R3 R4 6 ; R3:checker
028 MOVE R4 R1 ; R1:size_check
031 GETGV R5 $input
034 SEND R4 :call n=1
038 JMPNOT R4 070
042 MOVE R4 R2 ; R2:split
045 GETGV R5 $input
048 SEND R4 :call n=1
052 MOVE R5 R3 ; R3:checker
055 SEND R4 :zip n=1
059 BLOCK R5 I[8]
062 SENDB R4 :map n=0
066 SEND R4 :all? n=0
070 JMPNOT R4 084
074 STRING R5 L[0] ; Correct!
077 SSEND R4 :puts n=1
081 JMP 091
084 STRING R5 L[1] ; Incorrect...
087 SSEND R4 :puts n=1
091 RETURN R4
093 STOP
irep 0x55b61e516e20 nregs=6 nlocals=3 pools=0 syms=1 reps=0 ilen=18
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:s
007 SEND R3 :size n=0
011 LOADI R4 48
014 EQ R3 R4
016 RETURN R3
irep 0x55b61e516eb0 nregs=5 nlocals=3 pools=0 syms=1 reps=1 ilen=19
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 LOADI_0 R3 (0)
006 LOADI_6 R4 (6)
008 RANGE_EXC R3
010 BLOCK R4 I[0]
013 SENDB R3 :map n=0
017 RETURN R3
irep 0x55b61e516f60 nregs=7 nlocals=3 pools=0 syms=1 reps=0 ilen=25
local variable names:
R1:i
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 GETUPVAR R3 1 0
008 MOVE R4 R1 ; R1:i
011 LOADI R5 8
014 MUL R4 R5
016 LOADI R5 8
019 SEND R3 :[] n=2
023 RETURN R3
irep 0x55b61e517000 nregs=12 nlocals=3 pools=0 syms=2 reps=1 ilen=49
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:s
007 SEND R3 :chars n=0
011 BLOCK R4 I[0]
014 SENDB R3 :map n=0
018 LOADI R4 173
021 LOADI R5 187
024 LOADI R6 189
027 LOADI R7 189
030 LOADI R8 177
033 LOADI R9 176
036 LOADI R10 133
039 LOADI R11 173
042 ARRAY R4 R4 8
045 EQ R3 R4
047 RETURN R3
irep 0x55b61e517090 nregs=6 nlocals=3 pools=0 syms=2 reps=0 ilen=20
local variable names:
R1:c
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:c
007 SEND R3 :ord n=0
011 LOADI R4 254
014 SEND R3 :^ n=1
018 RETURN R3
irep 0x55b61e517120 nregs=12 nlocals=3 pools=0 syms=2 reps=1 ilen=48
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:s
007 SEND R3 :chars n=0
011 BLOCK R4 I[0]
014 SENDB R3 :map n=0
018 LOADI R4 55
021 LOADI R5 108
024 LOADI_0 R6 (0)
026 LOADI R7 40
029 LOADI R8 111
032 LOADI R9 42
035 LOADI R10 51
038 LOADI R11 59
041 ARRAY R4 R4 8
044 EQ R3 R4
046 RETURN R3
irep 0x55b61e5171f0 nregs=6 nlocals=3 pools=0 syms=2 reps=0 ilen=20
local variable names:
R1:c
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:c
007 SEND R3 :ord n=0
011 LOADI R4 95
014 SEND R3 :^ n=1
018 RETURN R3
irep 0x55b61e517280 nregs=12 nlocals=3 pools=0 syms=2 reps=1 ilen=49
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:s
007 SEND R3 :chars n=0
011 BLOCK R4 I[0]
014 SENDB R3 :map n=0
018 LOADI R4 253
021 LOADI R5 204
024 LOADI R6 145
027 LOADI R7 212
030 LOADI R8 145
033 LOADI R9 208
036 LOADI R10 253
039 LOADI R11 209
042 ARRAY R4 R4 8
045 EQ R3 R4
047 RETURN R3
irep 0x55b61e517350 nregs=6 nlocals=3 pools=0 syms=2 reps=0 ilen=20
local variable names:
R1:c
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:c
007 SEND R3 :ord n=0
011 LOADI R4 162
014 SEND R3 :^ n=1
018 RETURN R3
irep 0x55b61e5173e0 nregs=12 nlocals=3 pools=0 syms=2 reps=1 ilen=49
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:s
007 SEND R3 :chars n=0
011 BLOCK R4 I[0]
014 SENDB R3 :map n=0
018 LOADI R4 116
021 LOADI R5 57
024 LOADI R6 31
027 LOADI R7 55
030 LOADI R8 40
033 LOADI R9 115
036 LOADI R10 50
039 LOADI R11 115
042 ARRAY R4 R4 8
045 EQ R3 R4
047 RETURN R3
irep 0x55b61e5174b0 nregs=6 nlocals=3 pools=0 syms=2 reps=0 ilen=20
local variable names:
R1:c
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:c
007 SEND R3 :ord n=0
011 LOADI R4 64
014 SEND R3 :^ n=1
018 RETURN R3
irep 0x55b61e517540 nregs=12 nlocals=3 pools=0 syms=2 reps=1 ilen=49
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:s
007 SEND R3 :chars n=0
011 BLOCK R4 I[0]
014 SENDB R3 :map n=0
018 LOADI R4 195
021 LOADI R5 239
024 LOADI R6 244
027 LOADI R7 175
030 LOADI R8 195
033 LOADI R9 255
036 LOADI R10 168
039 LOADI R11 241
042 ARRAY R4 R4 8
045 EQ R3 R4
047 RETURN R3
irep 0x55b61e517610 nregs=6 nlocals=3 pools=0 syms=2 reps=0 ilen=20
local variable names:
R1:c
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:c
007 SEND R3 :ord n=0
011 LOADI R4 156
014 SEND R3 :^ n=1
018 RETURN R3
irep 0x55b61e5176a0 nregs=12 nlocals=3 pools=0 syms=2 reps=1 ilen=49
local variable names:
R1:s
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:s
007 SEND R3 :chars n=0
011 BLOCK R4 I[0]
014 SENDB R3 :map n=0
018 LOADI R4 30
021 LOADI R5 114
024 LOADI R6 75
027 LOADI R7 95
030 LOADI R8 29
033 LOADI R9 64
036 LOADI R10 80
039 LOADI R11 39
042 ARRAY R4 R4 8
045 EQ R3 R4
047 RETURN R3
irep 0x55b61e517770 nregs=6 nlocals=3 pools=0 syms=2 reps=0 ilen=20
local variable names:
R1:c
000 ENTER 1:0:0:0:0:0:0 (0x40000)
004 MOVE R3 R1 ; R1:c
007 SEND R3 :ord n=0
011 LOADI R4 45
014 SEND R3 :^ n=1
018 RETURN R3
irep 0x55b61e517800 nregs=7 nlocals=4 pools=0 syms=1 reps=0 ilen=16
local variable names:
R1:s
R2:f
000 ENTER 2:0:0:0:0:0:0 (0x80000)
004 MOVE R4 R2 ; R2:f
007 MOVE R5 R1 ; R1:s
010 SEND R4 :call n=1
014 RETURN R4
mruby のバイトコードやオペコードのドキュメント5を見ながら逆アセンブル結果を読解していきました。
irep 0x55b61e516c80の関数:OP_LAMBDAの用法が、ドキュメントを読んでも分かりませんでした。一方でCorrect!やIncorrect...の文字列やputs関数を呼び出しているらしいことから、もっとも外側の処理であることが推測できます。irep 0x55b61e516e20の関数: 引数のサイズが 48 ならtrueを、そうでないならfalseを返すようです。irep 0x55b61e516eb0の関数:[0,1,2,3,4,5].map(何か)を実行するようです。irep 0x55b61e516e20の関数で引数のサイズが 48 であることを確認しているため、 8 要素単位での処理を行っていそうです。irep 0x55b61e516f60の関数: R1のArrayから、Pythonでいう[(i*8):((i+1)*8)]を返すようです。本関数も 8 要素単位で処理を行うための関数のようです。irep 0x55b61e517000の関数: ブロックI[0]の出自が分かりませんでしたが、どうやらs.chars().map(:block) == [173,187,189,189,177,176,133,173]の比較結果を返すようです。irep 0x55b61e517090の関数: 数値引数cについてord(c) ^ 254を返すようです。
ここで、 irep 0x55b61e517090 の関数の ord(c) ^ 254 を、 irep 0x55b61e517000 で比較している数列 [173,187,189,189,177,176,133,173] へ適用してみると、 SECCON{S 文字列が得られました。やはりフラグを8文字ずつ検証しているようです。 irep 0x55b61e517120 以降の関数でも同様に、数列の比較や、異なる数値での XOR を行っています。それらの関数も同様にフラグを検証するものと考えました。
最終的なフラグを逆算して計算するPythonコードを以下に記載します。
#!/usr/bin/env python3 def decode(value_to_xor:int, expected:list[int])->str: result = "" for e in expected: result += chr(e ^ value_to_xor) return result print(decode(254, [173, 187, 189, 189, 177, 176, 133, 173]), end="") print(decode(95, [55, 108, 0, 40, 111, 42, 51, 59]), end="") print(decode(162, [253, 204, 145, 212, 145, 208, 253, 209]), end="") print(decode(64, [116, 57, 31, 55, 40, 115, 50, 115]), end="") print(decode(156,[195, 239, 244, 175, 195, 255, 168, 241]), end="") print(decode(45, [30, 114, 75, 95, 29, 64, 80, 39]), end="")
実行すると、フラグが SECCON{Sh3_w0uld_n3v3r_s4y_wh3r3_sh3_c4m3_fr0m} と分かります。
Allegro
King of the Hill 形式の問題の1つです。筆者なりにルールを要約すると、次の内容です。
- 決勝開催期間の 2 日間に渡った 6 フェーズで構成されます。
- フェーズごとに、低速な x86-64 ELF ファイルが与えられます(それぞれ prog-1, prog-2, ..., prog-6 と呼びます)。
- 与えられる各種 ELF ファイルは、標準入力を受け取り、各フェーズ固有の計算を行い、結果を出力する機能を持ちます。
- 競技者は、与えられた ELF ファイルを解析して計算内容を解明し、同一の計算をより高速に行う ELF ファイルを提出します。
- 1 ラウンドである 5 分ごとに、各チームの最終提出 ELF ファイルが自動的に実行されます。
- 0.1 秒単位で実行時間が測定され、国際決勝と国内決勝それぞれに分かれて、全 9 チーム中で早く実行終了するチームがより高い得点を得ます。
- 上位チームから順に 20, 16, 12, 9, 6, 4, 2, 1, 0 点を得ます。
- 実行時間が 3 秒を超える場合、当該チームのラウンドの順位は最下位になります。
- 入力に対して正しい計算結果を出力する必要があります。誤った出力を行ったチームも、ラウンドの順位が最下位になります。
- ラウンドが進行するに伴い、実行時に与えられる入力は難しくなります。簡単な順に baby, easy, medium, hard, lunatic と呼称されています。
- 0.1 秒単位で実行時間が測定され、国際決勝と国内決勝それぞれに分かれて、全 9 チーム中で早く実行終了するチームがより高い得点を得ます。
フェーズ 1 (Day 1 11:00 - 12:30)
与えられた ELF ファイルは次の機能のバイナリです。
int __fastcall main() { __int64 result; // rax unsigned __int64 value; // [rsp+0h] [rbp-10h] BYREF unsigned __int64 canary; // [rsp+8h] [rbp-8h] canary = __readfsqword(0x28u); __isoc99_scanf("%llu", &value); if ( value > 3 ) sleep(5u); result = f(value); printf("%llu\n", result); return 0; } __int64 __fastcall f(__int64 a1) { __int64 v2; // rbx __int64 v3; // rbx switch ( a1 ) { case 0LL: return 1LL; case 1LL: return 1LL; case 2LL: return 1LL; } v2 = f(a1 - 3); v3 = f(a1 - 2) + v2; return v3 - f(a1 - 1) + a1; }
上記バイナリが低速な理由と、変更した内容は次のとおりです。
- 標準入力から受け取る値が 4 以上の場合は
sleep(5u)を呼び出すため 5 秒待機します。そのため実行時間が 3 秒を超えることになり、タイムアウト扱いになります。- →
sleep関数呼び出しを単純に削除します。
- →
f関数が複数回の再帰で実装されています。引数の値の増加に伴い、計算時間が指数オーダーで増加します。- →
f関数の実装をループに変更します。これにより、引数の値の増加しても、計算時間を線形オーダーとなるように抑えます。
- →
最終的に使用したソースコードは次のとおりです。
#include<stdio.h> unsigned long long f(const unsigned long long arg) { if (arg <= 2){ return 1; } unsigned long long v0 = 1; unsigned long long v1 = 1; unsigned long long v2 = 1; unsigned long long result; for(unsigned long long i = 3; i <= arg; ++i){ auto temp2 = v0; auto temp3 = v1 + temp2; result = temp3 - v2 + i; v0 = v1; v1 = v2; v2 = result; } return v2; } int main(int argc, const char **argv, const char **envp) { unsigned long long v3; // rax unsigned long long value; // [rsp+0h] [rbp-10h] BYREF unsigned long long v6; // [rsp+8h] [rbp-8h] auto unused = scanf("%llu", &value); v3 = f(value); printf("%llu\n", v3); return 0; }
上記ソースコードをビルドしたバイナリは、最初 30 分間のラウンド 1 ~ 6 に対応する難易度 baby や、続く 30 分間のラウンド 7 ~ 12 に対応する難易度 easy の入力では他チームと同等の速度が出ていました。しかし本フェーズ最後 30 分間のラウンド 13 ~ 18 に対応する難易度 medium の入力では他チームから速度差をつけられてしまいました。高速化案として f 関数を線形オーダー実装ではなく、対数オーダーや定数オーダーで実装可能か考察していましたが、漸化式の + a1 要素をうまく吸収できませんでした。

フェーズ 2 (Day 1 12:30 - 14:30)
与えられた ELF ファイルの動作を理解するまでに時間がかかりました。 strace コマンドで動的解析すると /proc/self/exe を開いて何かしていることぐらいだけが分かったり、エントリーポイントの処理を逆コンパイルしても複雑であるため理解が困難だったりしたためです。
パッキングされている可能性を考慮して文字列を調べていると、 ELF 中に次の文字列が含まれていることに気付きました。
$Info: This file is packed with the UPX executable packer http://upx.sf.net $$Id: UPX 4.24 Copyright (C) 1996-2024 the UPX Team. All Rights Reserved. $
どうやら UPX でパックされているようです。しかし単純に upx -d prog-2 コマンドで展開を試みても upx: prog-2: NotPackedException: not packed by UPX で失敗しました。
与えられた ELF ファイルを調査すると、ファイル中に CTF! というマーカーらしいものが合計3箇所見つかりました。手元で適当な ELF 形式を upx コマンドで圧縮してみると UPX! マーカーが3箇所に付与されることが分かりました。そのため ELF 中の CTF! マーカーを UPX! マーカーへ変更し、改めて upx -d prog-2 コマンドを試すと、展開に成功しました。展開後の内容は次の内容です。
unsigned int __fastcall CalculateHash(const unsigned __int8 *ptr, unsigned __int64 length) { int j; // [rsp+18h] [rbp-18h] unsigned int hash; // [rsp+1Ch] [rbp-14h] unsigned __int64 i; // [rsp+28h] [rbp-8h] hash = -1; for ( i = 0LL; i < length; ++i ) { hash ^= ptr[i]; for ( j = 7; j >= 0; --j ) hash = (hash >> 1) ^ -(hash & 1) & 0x82F63B78; } return ~hash; } int __fastcall main() { unsigned int result; // eax unsigned __int64 length; // [rsp+10h] [rbp-10h] unsigned __int8 *ptr; // [rsp+18h] [rbp-8h] length = 0LL; ptr = (unsigned __int8 *)malloc(2uLL); while ( read(0, &ptr[length], 1uLL) == 1 ) { ptr = (unsigned __int8 *)realloc(ptr, ++length + 1); usleep(1000u); } result = CalculateHash(ptr, length); printf("%08x\n", result); free(ptr); return 0; }
上記バイナリが低速な理由と、最終的に変更した内容は次のとおりです。
readシステムコールの 1 回の呼び出しで 1 バイトのみ読み込んでいます。そのため入力全体を読み終わるまでにシステムコールが多数実行されます。- → 初期状態で大量にメモリを確保しておき、
readシステムコール 1 回で大量のバイトを読み込むようにします。
- → 初期状態で大量にメモリを確保しておき、
- ループ内部で
usleep(1000u)呼び出しが存在します。そのため 1 バイト読み込むごとに 1 秒待機します。- →
usleep関数呼び出しを単純に削除します。
- →
最終的に使用したソースコードは次のとおりです。
#include<cstdio> #include<cstdlib> #include<cstring> #include<sys/mman.h> #include<sys/stat.h> #include<sys/types.h> #include<unistd.h> #include<vector> #include<array> unsigned int CalculateHash(const unsigned char *src, unsigned long length) { int j; // [rsp+18h] [rbp-18h] unsigned int hash; // [rsp+1Ch] [rbp-14h] unsigned long i; // [rsp+28h] [rbp-8h] hash = -1; for ( i = 0LL; i < length; ++i ) { hash ^= src[i]; for ( j = 7; j >= 0; --j ) hash = (hash >> 1) ^ -(hash & 1) & 0x82F63B78; } return ~hash; } int main() { #define REQ_SIZE (1024*1024*1024) auto addr = (unsigned char*)mmap(NULL, REQ_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if(addr == MAP_FAILED) { perror("mmap"); exit(1); } size_t total_size = 0; while(true) { size_t read_size = read(0, addr+total_size, REQ_SIZE); if (read_size <= 0){ break; } total_size += read_size; } auto result = CalculateHash(addr, total_size); printf("%08x\n", result); return 0; }
フェーズ 2 での獲得スコアは、次の 2 点が要因で少なくなってしまいました。
- UPX のマーカーを修正すれば UPX 展開できることに気付くが遅れ、初提出がフェーズ開始から約 45 分後のラウンド 28 になった点。
- 上記ソースコードをビルドしたバイナリでは上位チームと比較して約 2 ~ 6 倍遅く、ラウンドの順位が 4 位となって獲得点数が 9 点となる場合が多かった点。
ハッシュ値計算を高速化できる余地があるように思いましたが、残念ながら高速化案が思いつきませんでした。

フェーズ 3 (Day 1 14:30 - 18:00)
与えられた ELF ファイルは、大まかに次の内容を持ちます。
- pocketpy6 ライブラリを使って、 Python コードの実行やインタープリター環境との入出力を行います。
- 標準入力からの受け取りのために
py_exec関数等で Python コードを実行します。ここで実行するPythonコードはバイナリ中に平文で埋め込まれています。 - 各種計算のために
py_getregやpy_binaryop等の関数を使用して、インタープリター環境中で計算します。 - なおシンボル情報が残っており関数名が分かるため、 pocketpy 由来の関数は一目瞭然です。
- 標準入力からの受け取りのために
- 独自の仮想マシンとして動作します。
- 状態として
uint32_t型のレジスタ 10 個を持ちます。 - 次の 9 種類のオペコードを解釈します。
- レジスタへの即値代入 1 種類
- レジスタ間の値コピー 1 種類
- 加減乗除 4 種類
JE,JNEに相当する条件付きジャンプ 2 種類- 無条件ジャンプ 1 種類
- 状態として
フェーズ 1 やフェーズ 2 の ELF ファイルとは異なり、本フェーズでは意図的な sleep 等の遅延はありません。どうやら pocketpy 経由での実行そのものが低速であるようです。C++で独自仮想マシンを再実装しました。最終的に使用したソースコードは次のとおりです。
#include <iostream> #include <cstdio> #include <cstring> #include <array> #include <cstddef> #include <cstdint> #include <vector> struct instruction { int opcode; int operands[3]; }; std::vector<instruction> g_instructions; std::size_t g_pc = 0; std::array<std::uint32_t, 10> g_register_array; void read_input() { while (true) { char line[512]; { auto scanf_result = std::scanf("%[^\n]", line); if (scanf_result != 1) { std::printf("Invalid line...\n"); exit(-99); } if (strcmp(line, "__EOF__") == 0) { return; } int a = getchar(); if (a != '\n') { ungetc(a, stdin); } } char buffer_opecode[512]; char buffer_operand[512]; { auto scanf_result = std::sscanf(line, "%s %s", buffer_opecode, buffer_operand); if (scanf_result != 2) { std::printf("Invalid line: %s\n", line); exit(-999); } } instruction inst{}; if (strcmp(buffer_opecode, "OP1") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u", &inst.operands[0], &inst.operands[1]); if (sscanf_result != 2) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP2") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u", &inst.operands[0], &inst.operands[1]); if (sscanf_result != 2) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP3") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u", &inst.operands[0], &inst.operands[1]); if (sscanf_result != 2) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP4") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u", &inst.operands[0], &inst.operands[1]); if (sscanf_result != 2) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP5") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u", &inst.operands[0], &inst.operands[1]); if (sscanf_result != 2) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP6") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u", &inst.operands[0], &inst.operands[1]); if (sscanf_result != 2) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP7") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u,%u", &inst.operands[0], &inst.operands[1], &inst.operands[2]); if (sscanf_result != 3) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP8") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u,%u,%u", &inst.operands[0], &inst.operands[1], &inst.operands[2]); if (sscanf_result != 3) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else if (strcmp(buffer_opecode, "OP9") == 0) { inst.opcode = (buffer_opecode[2] - '0'); auto sscanf_result = sscanf(buffer_operand, "%u", &inst.operands[0]); if (sscanf_result != 1) { std::printf("Invalid operand for %s: %s\n", buffer_opecode, buffer_operand); exit(-inst.opcode); } } else { printf("Invalid Opcode: %s\n", buffer_opecode); exit(-9999); } g_instructions.push_back(inst); } } int main() { read_input(); g_register_array.fill(0); g_pc = 0; while (g_pc < g_instructions.size()) { // fprintf(stderr, "pc: %d\n", (int)g_pc); const auto &inst = g_instructions[g_pc]; switch (inst.opcode) { case 1: g_register_array[inst.operands[0]] = inst.operands[1]; break; case 2: g_register_array[inst.operands[0]] = g_register_array[inst.operands[1]]; break; case 3: g_register_array[inst.operands[0]] += g_register_array[inst.operands[1]]; break; case 4: g_register_array[inst.operands[0]] -= g_register_array[inst.operands[1]]; break; case 5: g_register_array[inst.operands[0]] *= g_register_array[inst.operands[1]]; break; case 6: g_register_array[inst.operands[0]] /= g_register_array[inst.operands[1]]; break; case 7: if (g_register_array[inst.operands[0]] == g_register_array[inst.operands[1]]) { g_pc = inst.operands[2] - 1; } break; case 8: if (g_register_array[inst.operands[0]] != g_register_array[inst.operands[1]]) { g_pc = inst.operands[2] - 1; } break; case 9: g_pc = inst.operands[0] - 1; break; default: std::printf("Invalid opcode: %d\n", inst.opcode); exit(-99999); break; } ++g_pc; } for (std::size_t i = 0; i < g_register_array.size(); ++i) { printf("R%d: 0x%08x\n", (int)(i), (unsigned int)(g_register_array[i])); } }
フェーズ 3 では比較的高い得点を獲得できました。
- 初めてバイナリを提出できたのは、フェーズ開始から約 90 分後のラウンド 62 です。しかし当該ラウンド時点では正解している他チームが少なく、失点を抑えられました。
- ナイーブな C++ 再実装ですがそれなりに高速のようで、 1 ~ 3 位を達成できるラウンドが多かったです。
より高速にする案として「仮想マシン命令をインタープリターで毎回実行するのではなく、仮想マシン命令の読み込み後に機械語を動的生成して直接実行する」案が出ましたが、残念ながら実装しきれませんでした。上位チームでは実装済みのチームもあるかもしれません。
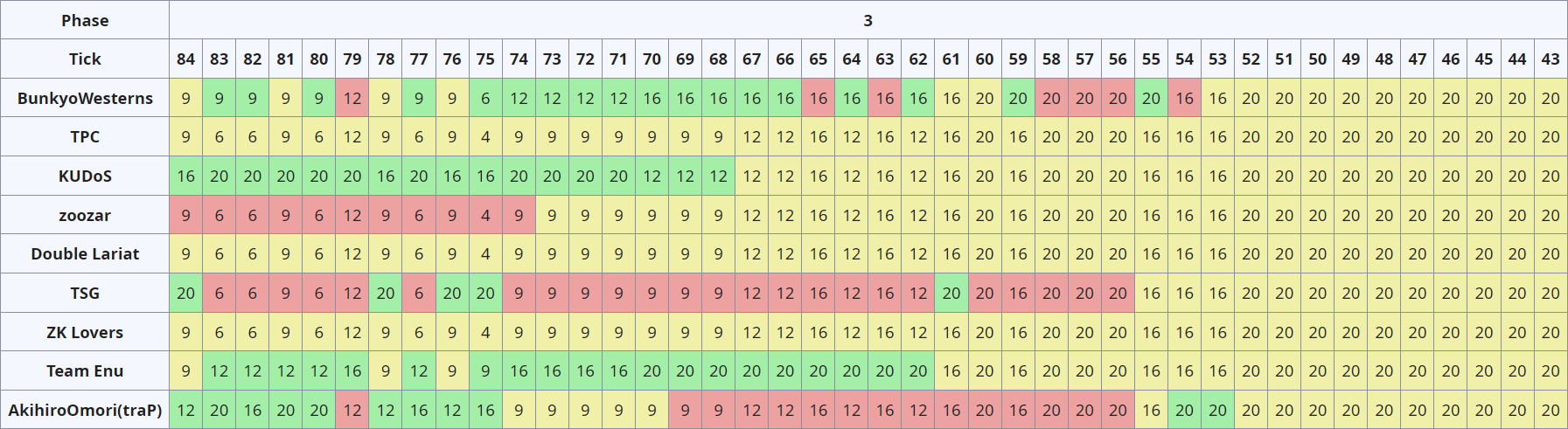
フェーズ 4 (Day 2 10:00 - 12:00)
与えられた ELF ファイルは PyInstaller7 製のバイナリです。元の Python コードを抽出し、逆コンパイルした結果は次の内容です。
import hashlib import time def crack(data_prefix: bytes, hash_prefix: str, offset: int, f) -> bytes: for c1 in range(256): for c2 in range(256): for c3 in range(256): for c4 in range(256): time.sleep(0.001) data = bytes([c1, c2, c3, c4]) h = f(data_prefix + data).hexdigest() if h[offset:offset + len(hash_prefix)] == hash_prefix.lower(): return data else: return if __name__ == '__main__': args = input().split() data_prefix = bytes.fromhex(args[0]) hash_prefix = args[1] offset = int(args[2]) f = hashlib.sha256 if len(args) > 3: if args[3] == 'md5': f = hashlib.md5 elif args[3] == 'sha512': f = hashlib.sha512 print(crack(data_prefix, hash_prefix, offset, f).hex())
指定されたデータの後ろに何らかの 4 バイトを追加してハッシュ値を計算し、16進数表記で目的のハッシュ値となる 4 バイトを総当りで探索する内容です。ハッシュ関数は MD5, SHA256, SHA512 から選択できます。
最終的に使用したソースコードは次のとおりです。
#include <stdio.h> #include <openssl/sha.h> #include <openssl/md5.h> #include <vector> #include <string_view> #include <cstdlib> #include <cstring> #include <array> #include <string> int unhex_char(char c) { switch (c) { case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': return c - '0'; case 'a': case 'b': case 'c': case 'd': case 'e': case 'f': return c - 'a' + 10; case 'A': case 'B': case 'C': case 'D': case 'E': case 'F': return c - 'A' + 10; default: printf("Unknown char: %c\n", c); std::exit(-3); } } std::vector<unsigned char> unhex_string(std::string_view str) { std::vector<unsigned char> v; v.reserve(str.size() / 2); for (size_t i = 0; i < str.size() / 2; ++i) { int x = unhex_char(str[2 * i + 0]); int y = unhex_char(str[2 * i + 1]); int z = (x << 4) | y; v.push_back(z); } return v; } std::string to_hex(const std::vector<unsigned char>& vec) { std::string result; char buffer[256]; for(auto v : vec) { sprintf(buffer, "%02x", v); result.push_back(buffer[0]); result.push_back(buffer[1]); } return result; } void print_hex(const std::vector<unsigned char>& vec) { for(auto v : vec) { printf("%02x", v); } printf("\n"); } template <class F> std::vector<unsigned char> crack(const std::vector<unsigned char> &data_prefix, std::string_view hash_prefix_hex, int offset, F f) { std::vector<unsigned char> calculated_hash_raw; calculated_hash_raw.resize(256); std::vector data(data_prefix.begin(), data_prefix.end()); data.push_back(0); data.push_back(0); data.push_back(0); data.push_back(0); const auto data_size = data.size(); for (int i = 0; i < 256; ++i) { data[data_size - 4] = i; for (int j = 0; j < 256; ++j) { data[data_size - 3] = j; for (int k = 0; k < 256; ++k) { data[data_size - 2] = k; for (int l = 0; l < 256; ++l) { data[data_size - 1] = l; f(data.data(), data.size(), calculated_hash_raw.data()); auto hash_hex = to_hex(calculated_hash_raw); if (memcmp(hash_hex.data() + offset, hash_prefix_hex.data(), hash_prefix_hex.size()) == 0) { std::vector<unsigned char> xxx{(unsigned char)i,(unsigned char)j,(unsigned char)k,(unsigned char)l}; return xxx; } } } } } printf("Can not crack!\n"); exit(-42); } int main() { char line[4096]; int read_result_1 = std::scanf("%[^\n]", line); if (read_result_1 != 1) { printf("Failed to read line\n"); exit(-2); } char data_prefix_hex[4096], hash_prefix_hex[4096], hash_type[4096]{}; int offset; int read_result_2 = sscanf(line, "%s%s%d%s", data_prefix_hex, hash_prefix_hex, &offset, hash_type); if (read_result_2 < 3) { printf("Failed to read\n"); exit(-1); } auto data_prefix_raw = unhex_string(data_prefix_hex); if (strcmp(hash_type, "md5") == 0) { print_hex(crack(data_prefix_raw, hash_prefix_hex, offset, MD5)); } else if (strcmp(hash_type, "sha512") == 0) { print_hex(crack(data_prefix_raw, hash_prefix_hex, offset, SHA512)); } else { print_hex(crack(data_prefix_raw, hash_prefix_hex, offset, SHA256)); } }
フェーズ 4 では、あまり点数を得られませんでした。
- 上記ソースコードは OpenSSL の
MD5,SHA256,SHA512関数を使って、ナイーブに総当たりを行う内容です。ただし次の高速化の余地が存在します。- ハッシュ関数の内部状態は
data_prefixまでの計算はすべて同一になります。その後に続く 4 バイトのみが変化するため、data_prefixまでの計算を行う必要はないため、キャッシュできる余地があります。 - ハッシュ計算結果が 16 進数表記の
hash_prefixを含むかどうか比較する際、ハッシュ値から Hex エンコードを毎回行ってstd::stringインスタンスを作成しています。 Hex エンコードを省略して判定できれば高速化できる余地があります。
- ハッシュ関数の内部状態は
- しかし改善を試みても、エンバグしてしまったのか実行時間が 3 秒を超えてタイムアウトするようになったため、上記ソースコードを使い続けることになってしまいました。
- また、 PyInstaller からの元スクリプト抽出や上記ソースコードの実装にも苦労したため、初めての得点を得られたのがフェーズ開始約 75 分後のラウンド 100 になってしまいました。
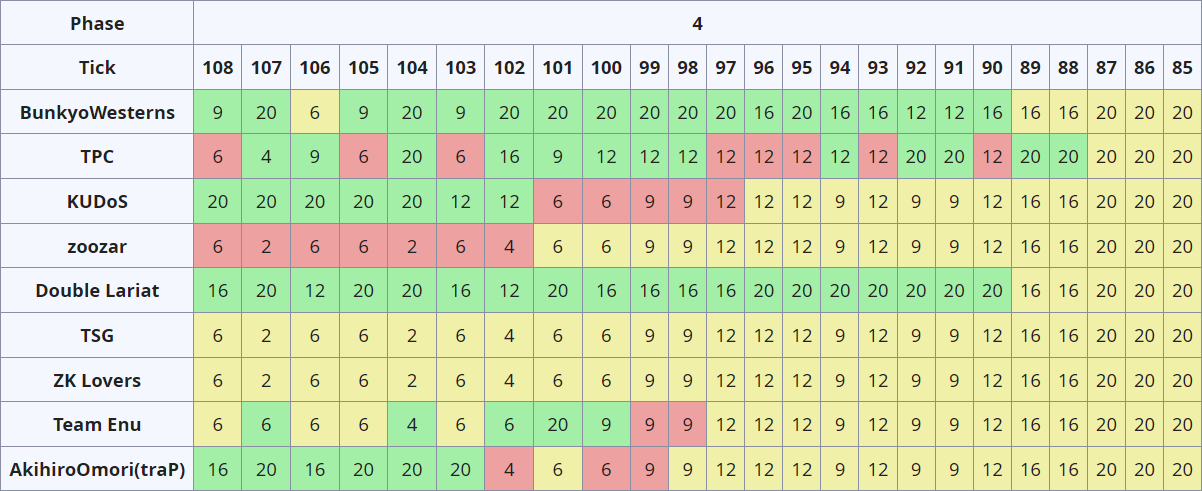
フェーズ 5 (Day 2 12:00 - 14:30)
与えられた ELF ファイルは、 glibc が動的リンクされているにもかかわらず、ファイルサイズが 1MiB 以上ある大きい内容です。内容を調査すると $LuaVersion: Lua 5.4.6 文字列の存在や、後述する main 関数が呼び出す関数名から、 Lua バイトコードを含む内容のようです。 main 関数を逆コンパイルした結果は次の内容です。
int __fastcall main() { __int64 v1; // rax __int64 v2; // rax unsigned __int64 mat_size; // [rsp+0h] [rbp-50h] BYREF __int64 element_value; // [rsp+8h] [rbp-48h] BYREF unsigned __int64 i_1; // [rsp+10h] [rbp-40h] unsigned __int64 j_1; // [rsp+18h] [rbp-38h] unsigned __int64 i_2; // [rsp+20h] [rbp-30h] unsigned __int64 j_2; // [rsp+28h] [rbp-28h] unsigned __int64 i_3; // [rsp+30h] [rbp-20h] unsigned __int64 j_3; // [rsp+38h] [rbp-18h] __int64 luaState; // [rsp+40h] [rbp-10h] unsigned __int64 canary; // [rsp+48h] [rbp-8h] canary = __readfsqword(0x28u); luaState = luaL_newstate(); if ( !luaState ) return 1; if ( !(unsigned int)luaL_loadbufferx(luaState, "\x1BLuaT", *(int *)((char *)&loc_401F04 + 3), "embedded", 0LL) && !(unsigned int)lua_pcallk(luaState, 0LL, 0xFFFFFFFFLL, 0LL, 0LL, 0LL) ) { _isoc99_scanf("%lu", &mat_size); lua_getglobal(luaState, "G"); lua_getglobal(luaState, "F"); lua_getglobal(luaState, "F"); lua_createtable(luaState, (unsigned int)mat_size, 0LL); for ( i_1 = 0LL; i_1 < mat_size; ++i_1 ) { lua_createtable(luaState, (unsigned int)mat_size, 0LL); for ( j_1 = 0LL; j_1 < mat_size; ++j_1 ) { _isoc99_scanf("%lld", &element_value); lua_pushinteger(luaState, element_value); lua_rawseti(luaState, 4294967294LL, j_1 + 1); } lua_rawseti(luaState, 4294967294LL, i_1 + 1); } lua_createtable(luaState, (unsigned int)mat_size, 0LL); for ( i_2 = 0LL; i_2 < mat_size; ++i_2 ) { lua_createtable(luaState, (unsigned int)mat_size, 0LL); for ( j_2 = 0LL; j_2 < mat_size; ++j_2 ) { _isoc99_scanf("%lld", &element_value); lua_pushinteger(luaState, element_value); lua_rawseti(luaState, 4294967294LL, j_2 + 1); } lua_rawseti(luaState, 4294967294LL, i_2 + 1); } if ( !(unsigned int)lua_pcallk(luaState, 2LL, 1LL, 0LL, 0LL, 0LL) ) { lua_pushvalue(luaState, 0xFFFFFFFFLL); if ( !(unsigned int)lua_pcallk(luaState, 2LL, 1LL, 0LL, 0LL, 0LL) && !(unsigned int)lua_pcallk(luaState, 1LL, 1LL, 0LL, 0LL, 0LL) ) { for ( i_3 = 0LL; i_3 < mat_size; ++i_3 ) { lua_rawgeti(luaState, 0xFFFFFFFFLL, i_3 + 1); putchar('['); for ( j_3 = 0LL; j_3 < mat_size; ++j_3 ) { lua_rawgeti(luaState, 0xFFFFFFFFLL, j_3 + 1); if ( j_3 == mat_size - 1 ) { v1 = lua_tointegerx(luaState, 0xFFFFFFFFLL, 0LL); printf("%lld", v1); } else { v2 = lua_tointegerx(luaState, 0xFFFFFFFFLL, 0LL); printf("%lld, ", v2); } lua_settop(luaState, 4294967294LL); } puts("]"); lua_settop(luaState, 4294967294LL); } } } } lua_close(luaState); return 0; }
ELF に埋め込まれた Lua バイトコードを逆コンパイルした結果は次の内容です。
-- filename: @main.lua -- version: lua54 -- line: [0, 0] id: 0 H = function(base, step, count) -- line: [1, 12] id: 1 if count < 0 then for r6_1 = 1, -count, 1 do base = base - step end else for r6_1 = 1, count, 1 do base = base + step end end return base end G = function(mat_g) -- line: [14, 23] id: 2 local result_g = {} for g_i = 1, #mat_g[1], 1 do result_g[g_i] = {} for g_j = 1, #mat_g, 1 do result_g[g_i][g_j] = mat_g[g_j][g_i] end end return result_g end F = function(map_a, map_b) -- line: [25, 37] id: local result_f = {} for f_i = 1, #map_a, 1 do result_f[f_i] = {} for f_j = 1, #map_a, 1 do result_f[f_i][f_j] = 0 for f_k = 1, #map_a, 1 do result_f[f_i][f_j] = H(result_f[f_i][f_j], map_a[f_i][f_k], map_b[f_k][f_j]) end end end return result_f end
Lua バイトコードで定義された 3 個の関数は、次の役割を持つようです。
H: 数値を 3 個取りa + b * cを非効率に計算して返します。G: 行列を 1 個取り、転置行列を返します。F: 行列を 2 個取り、行列積を計算して返します。
main 関数全体としてどのような計算を行うかは逆コンパイル結果を読んでも今ひとつ分かりませんでしたが、実験すると次の計算を行うこと分かりました。
- 整数 1 つを読み込みます。それを正方行列のサイズとして今後扱います。
- 整数成分を要素とする正方行列を 2 つ読み込みます。
- 読み込んだ 2 つの正方行列をそれぞれ
a,bとすると、(a*b*a*b)^⊤を計算して出力します。
高速化のために実装した内容は次のとおりです。
- 小さいサイズでの行列積の計算は
N^3かかるという前提と、適切なアルゴリズムなら 3 秒以内に実行が終わるという想定から、確保する行列サイズを1024^2の固定長で表現します。 - 先に
a*bを計算し、その結果を自乗することで、掛け算 2 回でa*b*a*bを計算します。 - 転置行列の計算は行わず、代わりに結果出力時のループ順で表現します。
最終的に使用したソースコードは次のとおりです。
#include <cstdio> #include <cstdlib> constexpr int MAT_SIZE = 1024; void read_mat( long long dst[MAT_SIZE][MAT_SIZE], int mat_size) { for (int i = 0; i < mat_size; ++i) { for (int j = 0; j < mat_size; ++j) { auto x = scanf("%lld", &dst[i][j]); if (x != 1) { exit(-1); } } } } void mul( long long dst[MAT_SIZE][MAT_SIZE], const long long a[MAT_SIZE][MAT_SIZE], const long long b[MAT_SIZE][MAT_SIZE], int mat_size) { for (int i = 0; i < mat_size; ++i) { for (int j = 0; j < mat_size; ++j) { for (int k = 0; k < mat_size; ++k) { dst[i][j] += a[i][k] * b[k][j]; } } } } long long a[MAT_SIZE][MAT_SIZE]{}; long long b[MAT_SIZE][MAT_SIZE]{}; long long ab[MAT_SIZE][MAT_SIZE]{}; long long abab[MAT_SIZE][MAT_SIZE]{}; int main() { int mat_size; { auto x = scanf("%d", &mat_size); if (x != 1) { return -1; } } read_mat(a, mat_size); read_mat(b, mat_size); mul(ab, a, b, mat_size); mul(abab, ab, ab, mat_size); for (int i = 0; i < mat_size; ++i) { for (int j = 0; j < mat_size; ++j) { printf("%s", j == 0 ? "[" : ", "); printf("%lld", abab[j][i]); // transpose } printf("]\n"); } }
フェーズ 5 でも、あまり点数を得られませんでした。
- 入出力を再現できるバイナリの提出が遅れてしまいました。初めての提出がフェーズ開始後約 60 分後のラウンド 121 と遅れてしまいました。かつ提出初期は出力が合わない状況であり、初めて正解できたのがフェーズ開始後約 80 分後のラウンド 125 になってしまいました。
- 高速化する案を思いつきませんでした。行列積の計算でのループ順序を逆転させたりしましたが、むしろ遅くなってしまいました。
- なお、後のフェーズ 6 での調査中に、行列積を高速に計算するにはループ順を
i,k,jにすればいいとの情報がありました。 - 一方で、自チームの計算時間が 2.8 秒のラウンドでも、首位チームは 0.2 秒で計算を終えていました。本質的な高速化方法があるように思います。
- なお、後のフェーズ 6 での調査中に、行列積を高速に計算するにはループ順を

フェーズ 6 (Day 2 14:30 - 17:00)
与えられた ELF ファイルは、他スクリプトのインタープリター等を持っていないという意味で、純粋なバイナリです。一方で cpuid , mfence 命令が多用されています。しかしバイナリ内容を解析するとそれらの命令は無意味であるようだったため、バイナリパッチで除去しました。不要な命令を除去した後のバイナリです。
int __fastcall main() { unsigned __int64 value2; // [rsp+0h] [rbp-60h] BYREF unsigned __int64 value3; // [rsp+8h] [rbp-58h] BYREF unsigned __int64 loop_count; // [rsp+10h] [rbp-50h] BYREF unsigned __int64 bit_shuffled; // [rsp+18h] [rbp-48h] unsigned __int64 loop_index; // [rsp+20h] [rbp-40h] unsigned __int64 bit_1; // [rsp+28h] [rbp-38h] unsigned __int64 bit_2; // [rsp+30h] [rbp-30h] __int64 v8; // [rsp+38h] [rbp-28h] unsigned __int64 i; // [rsp+40h] [rbp-20h] unsigned __int64 canary; // [rsp+48h] [rbp-18h] canary = __readfsqword(0x28u); __isoc99_scanf("%lu", &loop_count); __isoc99_scanf("%lu", &value2); __isoc99_scanf("%lu", &value3); for ( loop_index = 0LL; loop_index < loop_count; ++loop_index ) { bit_shuffled = 0LL; for ( bit_1 = 0LL; bit_1 <= 31; ++bit_1 ) bit_shuffled += ((value2 >> (2 * (unsigned __int8)bit_1)) & 1) << bit_1;// 0-indexed基準で偶数bit for ( bit_2 = 0LL; bit_2 <= 31; ++bit_2 ) bit_shuffled += ((value2 >> (2 * (unsigned __int8)bit_2 + 1)) & 1) << ((unsigned __int8)bit_2 + 32);// 0-indexed基準で奇数bit value2 = bit_shuffled; v8 = 0LL; for ( i = 0LL; i <= 63; ++i ) { if ( ((value3 >> i) & 1) != 0 ) ++v8; } value3 ^= value2 << v8; // << popcount(value3) v8 = (value3 >> 7) & 1; v8 += (2 * (unsigned __int8)(value3 >> 15)) & 2; v8 += (4 * (unsigned __int8)(value3 >> 23)) & 4; v8 += (8 * (unsigned __int8)(value3 >> 31)) & 8; v8 += (16 * (unsigned __int8)(value3 >> 39)) & 0x10; v8 += (32 * (unsigned __int8)(value3 >> 47)) & 0x20; v8 += ((unsigned __int8)(value3 >> 55) << 6) & 0x40; v8 += value3 >> 63 << 7; value2 ^= value3 << v8; value3 ^= value2; bit_shuffled = (unsigned int)((_DWORD)value2 << 24); bit_shuffled += value2 >> 8 << 56; bit_shuffled += (value2 >> 16 << 48) & 0xFF000000000000LL; bit_shuffled += (unsigned __int16)((unsigned __int16)(value2 >> 24) << 8); bit_shuffled += value2 & 0xFF00000000LL; bit_shuffled += (value2 >> 40 << 16) & 0xFF0000; bit_shuffled += BYTE6(value2); bit_shuffled += HIBYTE(value2) << 40; value2 = bit_shuffled; } printf("%lu\n", value2); return 0; }
ループ中で大きく4種類の計算を行っています。
- 64-bit 整数について 0-indexed 基準で偶数 bit を下位 32-bit へ、奇数 bit を上位 32-bit へ移動
- 64-bit 整数について 2 進数表現時に 1 であるビットの数を数えて、ビットシフト演算に使用
- 64-bit 整数について 7, 15, 23, 31, 39, 47, 55, 63-bit 目を集めて 8-bit 整数へ変換
- 64-bit 整数について 8-bit ごとに分割して位置を入れ替えて、新しい 64-bit 整数へ変換
2 種類目の計算は popcnt 命令で効率的に計算できます。最終的に使用したソースコードは次のとおりです。
#include <cstdio> #include <cstdint> #include <bit> #include <tuple> #include <immintrin.h> #pragma GCC optimize("unroll-loops") int main() { uint64_t value2; // [rsp+0h] [rbp-60h] BYREF uint64_t value3; // [rsp+8h] [rbp-58h] BYREF uint64_t loop_limit; // [rsp+10h] [rbp-50h] BYREF uint64_t bit_shuffled; // [rsp+18h] [rbp-48h] uint64_t loop_index; // [rsp+20h] [rbp-40h] int64_t v11; // [rsp+38h] [rbp-28h] std::ignore = scanf("%lu", &loop_limit); std::ignore = scanf("%lu", &value2); std::ignore = scanf("%lu", &value3); for ( loop_index = 0LL; loop_index < loop_limit; ++loop_index ) { // SIMD等でループをなくしたい bit_shuffled = 0LL; for (int bit_1 = 0LL; bit_1 <= 31; ++bit_1 ) bit_shuffled += ((value2 >> (2 * (unsigned char)bit_1)) & 1) << bit_1;// 0-indexed基準で偶数bit for (int bit_2 = 0LL; bit_2 <= 31; ++bit_2 ) bit_shuffled += ((value2 >> (2 * (unsigned char)bit_2 + 1)) & 1) << ((unsigned char)bit_2 + 32);// 0-indexed基準で奇数bit value2 = bit_shuffled; { int bitShiftCount = (value3 == 0 ? 0 : __builtin_popcountll(value3)); value3 ^= value2 << bitShiftCount; } // 7, 15, 23, 31, 39, 47, 55, 63 -bit 目を集めている // SIMDの余地がありそう v11 = (value3 >> 7) & 1; v11 += (2 * (unsigned char)(value3 >> 15)) & 2; v11 += (4 * (unsigned char)(value3 >> 23)) & 4; v11 += (8 * (unsigned char)(value3 >> 31)) & 8; v11 += (16 * (unsigned char)(value3 >> 39)) & 0x10; v11 += (32 * (unsigned char)(value3 >> 47)) & 0x20; v11 += ((unsigned char)(value3 >> 55) << 6) & 0x40; v11 += value3 >> 63 << 7; value2 ^= value3 << v11; value3 ^= value2; // SIMD化できそう bit_shuffled = (unsigned int)((unsigned int)value2 << 24); // [ 0, 8) -> [24:] bit_shuffled += value2 >> 8 << 56; // [ 8, 16) -> [56:] bit_shuffled += (value2 >> 16 << 48) & 0xFF000000000000LL; // [16, 24) -> [48:] bit_shuffled += (unsigned short)((unsigned short)(value2 >> 24) << 8); // [24, 32) -> [8:] bit_shuffled += value2 & 0xFF00000000LL; // [32, 40)? -> [32:] bit_shuffled += (value2 >> 40 << 16) & 0xFF0000; // [40, 48) -> [16:] bit_shuffled += (value2 >> 48) & 0xFF; // [48, 56) -> [0:] bit_shuffled += ((value2 >> 56) & 0xFF) << 40; // [56, 64) -> [40:] value2 = bit_shuffled; } printf("%lu\n", value2); return 0; }
フェーズ 6 では、序盤では比較的良い順位を達成できました。一方で中盤以降では他チームの高速化に追従できず、あまり点数を得られませんでした。
SIMD 化できる余地が多く存在する計算内容であるため、 SIMD 化できればできるほど速度に貢献する内容と思います。
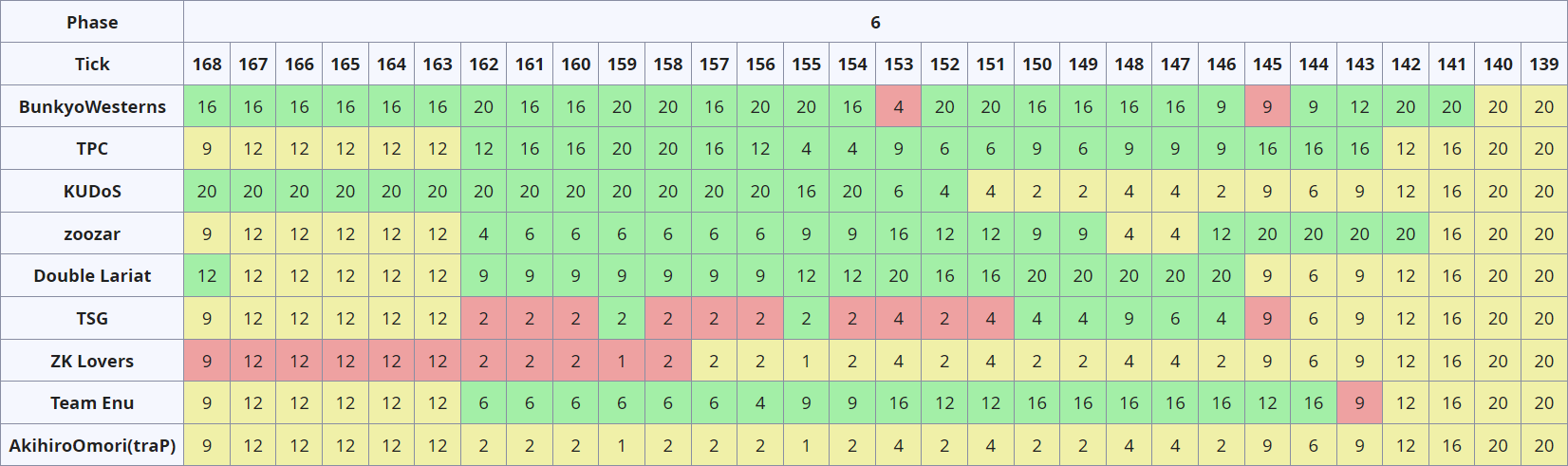
Allegro 全体の結果
全 6 フェーズ、 168 ラウンドが終了した後の Allegro 問題単体のスコアボードです。

Team Enu は Allegro では 2190-pts で 5 位となりました。
実際は順位表だけではなくスコア遷移グラフも表示されていたのですが、最終結果を撮影し忘れてしまったため省略します。
おわりに
今回の決勝のように、会場に集まって CTF へ参加するのは筆者にとって初めての経験になりました。正解フラグが提出されるたびに、音声とともに投影映像で正解チームや問題が表示されており、盛り上がりを感じました。
コンテスト内容として特に印象深いのが、 KotH 形式が非常に慌ただしくはあるものの、楽しめたということです。筆者が取り組んでいた Allegro 問題では、数時間ごとにお題となるバイナリが切り替わる上に、バイナリ解析やソースコード抽出、必要に応じて処理の再実装やアルゴリズム改善等、幅広い能力が高い強度で求められる内容でした。必要な高速化手法はバイナリによって異なるため、様々な観点やレイヤーでの発想が求められる点が面白いものでした。
そのような素晴らしいコンテストを運営いただいた、コンテスト作問者様や会場ネットワーク担当者様、 SECCON 全体の運営者様、およびすべての関係者様へ感謝を捧げます。ありがとうございました。
最後に、 SECCON CTF 決勝会場等の写真を掲載して本記事を締めくくります。


