はじめに
こんにちは!システム開発担当の林です!本稿では、我々が開発しているセキュリティ学習プラットフォーム(以下、セキュリティPF)で提供しているAI機能について解説します。
AI機能
NFLabs.ではサイバーセキュリティ研修を提供しています。一般に、講義時間中は詰まったり分からないことがあれば講師や他の受講生に質問することができますが、自己学習ではそのようなリアルタイムのサポートを受けることが出来ません。このセキュリティPFはNFLabs.の研修や学術機関などに提供予定で、その中でもこのAI機能は講義時間外・自己学習時に、学習者の手を止めないためのサポートの役割を果たします。
1. スキル分析
このセキュリティPFには「スキル」という概念があります。そのスキルにおいての習熟度(スキルレベル)を判定することがこれらのAI機能のベースとなっています。
スキル設計
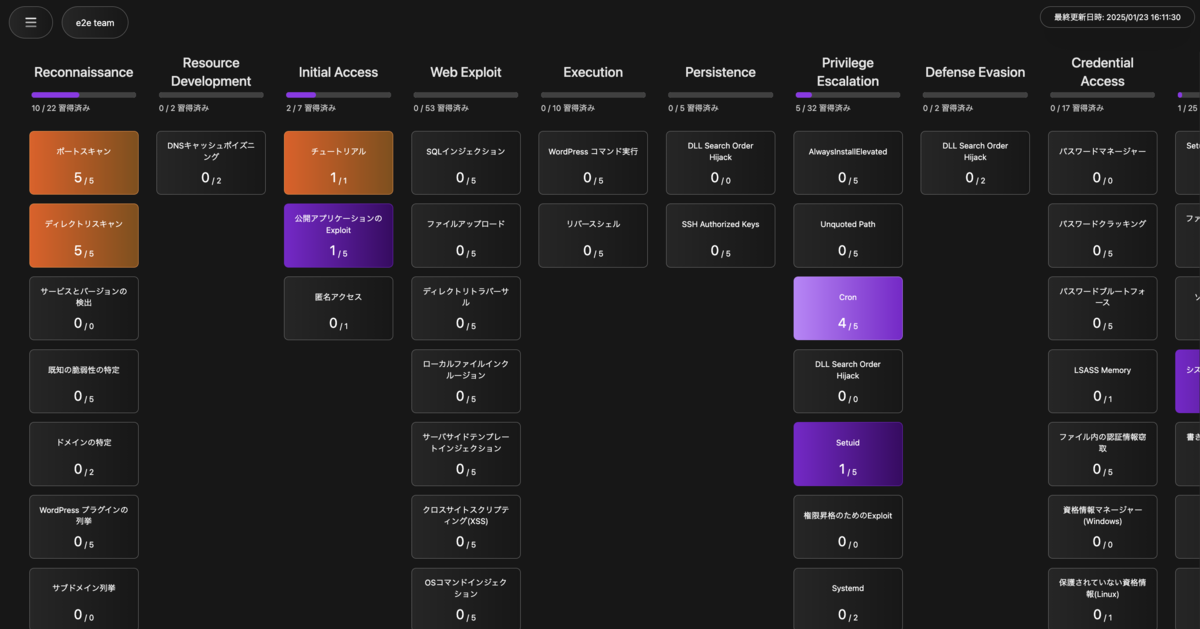
このセキュリティPFにおけるスキル体系はMITRE ATT&CKをベースとして作成しています。MITRE ATT&CKは米国NPOのMITREによる、攻撃技術・手法を体系的にまとめたナレッジベースで、世界で広く使われています。我々もそれをベースに採用することで、学習者が自身のスキル習熟度を(概ね)世界的な標準の尺度で俯瞰して確認できるようになります。
このセキュリティPFではそのスキル設計を「スキルマップ」という形で表現しています。それぞれのスキルにはレベル0からレベル5の独自の段階付けを行なっており、後述のログ収集基盤とAIによってレベル判定を実施しています。これにより、スキル習熟の広さと深さのどちらも判定できる仕組みとなっています。
また、このスキル判定の特長として、「問題に回答できたか」「フラグを取得できたか」等の結果だけではなく、攻略する上で「どのようなコマンドを実行したか」「コマンドオプションは適切だったか」「コマンドの出力結果を正しく理解しているか」など実際の学習者の操作を参照していることが挙げられます。これが技術の表面的な理解度ではなく、その技術を「本質的に理解しているか」を判断するのに寄与します。
インフラ (ログ収集・分析基盤)
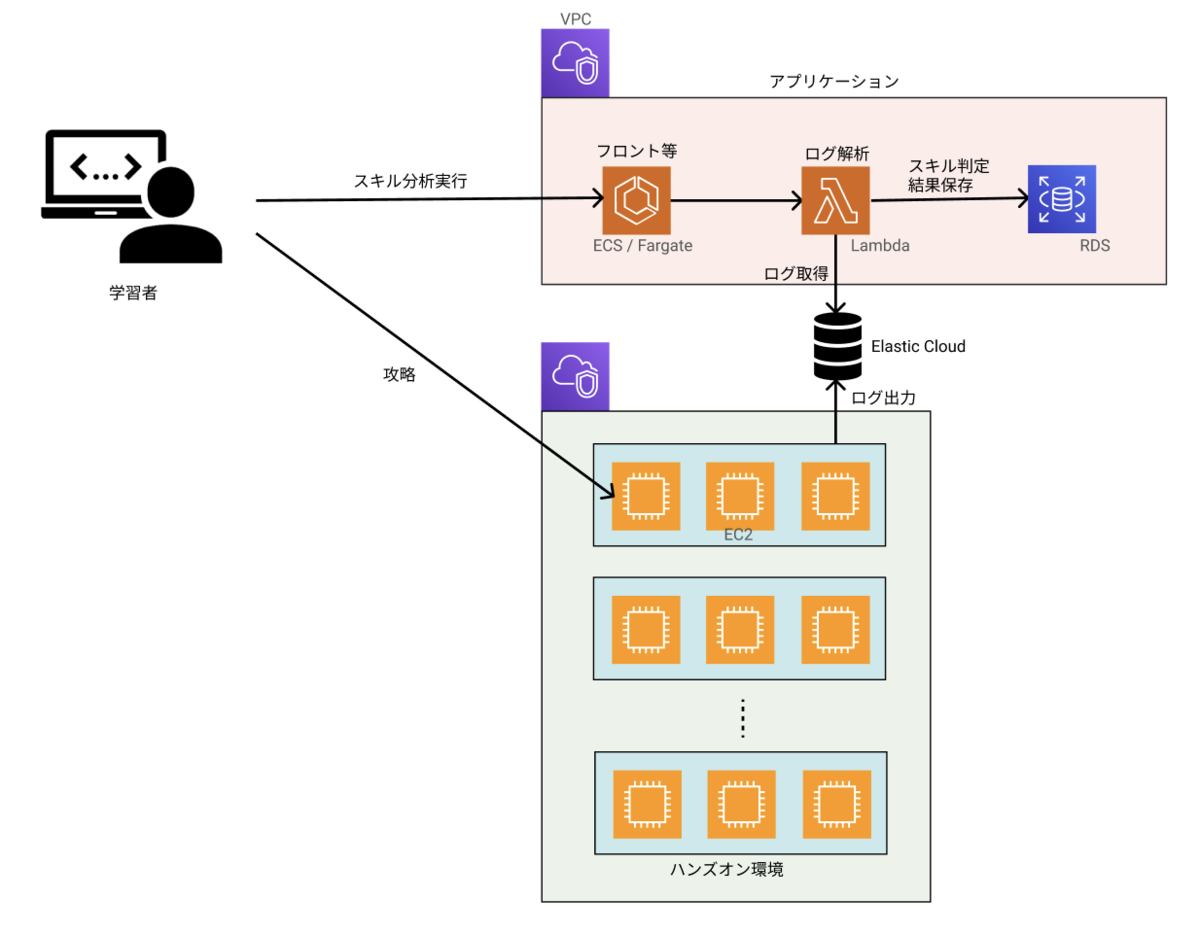
学習者のチャレンジ攻略に関する様々なログがリアルタイムにElastic Cloudに蓄積されます。スキル分析を実行するとこの膨大なログから必要なログが抽出・分析され、その時点でのスキル習熟度が攻略中のチャレンジに紐づくスキルの該当レベルに到達してるか否かが判定されます。
余談ですが、該当のスキルレベルに到達すると以下のようなリワードが表示され、少し嬉しい気持ちになります。こういった些細な遊び要素もゲーミフィケーションの一環として学習者のモチベーション維持に寄与します。
(↑見辛いですが、レベルアップのアニメーションと共に紙吹雪が舞っています)
このセキュリティPFにおけるゲーミフィケーション要素についてはまた別の機会に詳しく紹介します。
2. アドバイス
前述のログ収集基盤を活用してLLM・チャットbotによるアドバイス機能も実現しています。学習者は攻略に詰まったときに、チャットbotにアドバイスを求めることができます。このとき、チャットbotはログ収集基盤からその学習者の直近のログを取得・分析し、どこまで理解できているか・この後なにをすべきなのかを判断し、学習者に伝えます。学習者はこのアドバイスを元に自力で調査・攻略を再開します。
LLMチャットbotの難しさとして「答えを言ってはならない」が「無意味なアドバイスをしてはならない」という絶妙なレベルにチューニングする必要があることです。LLM自体には攻略手順をあらかじめ教える必要があるため、検証当初はチャットbotが次のコマンドやオプションをそのまま喋ってしまったり、プロンプトインジェクションでシステムプロンプトを喋ってしまったりということが起きました。様々なチューニングを施し現在は安定して動いていますが、まだまだ改善の余地はありそうです。
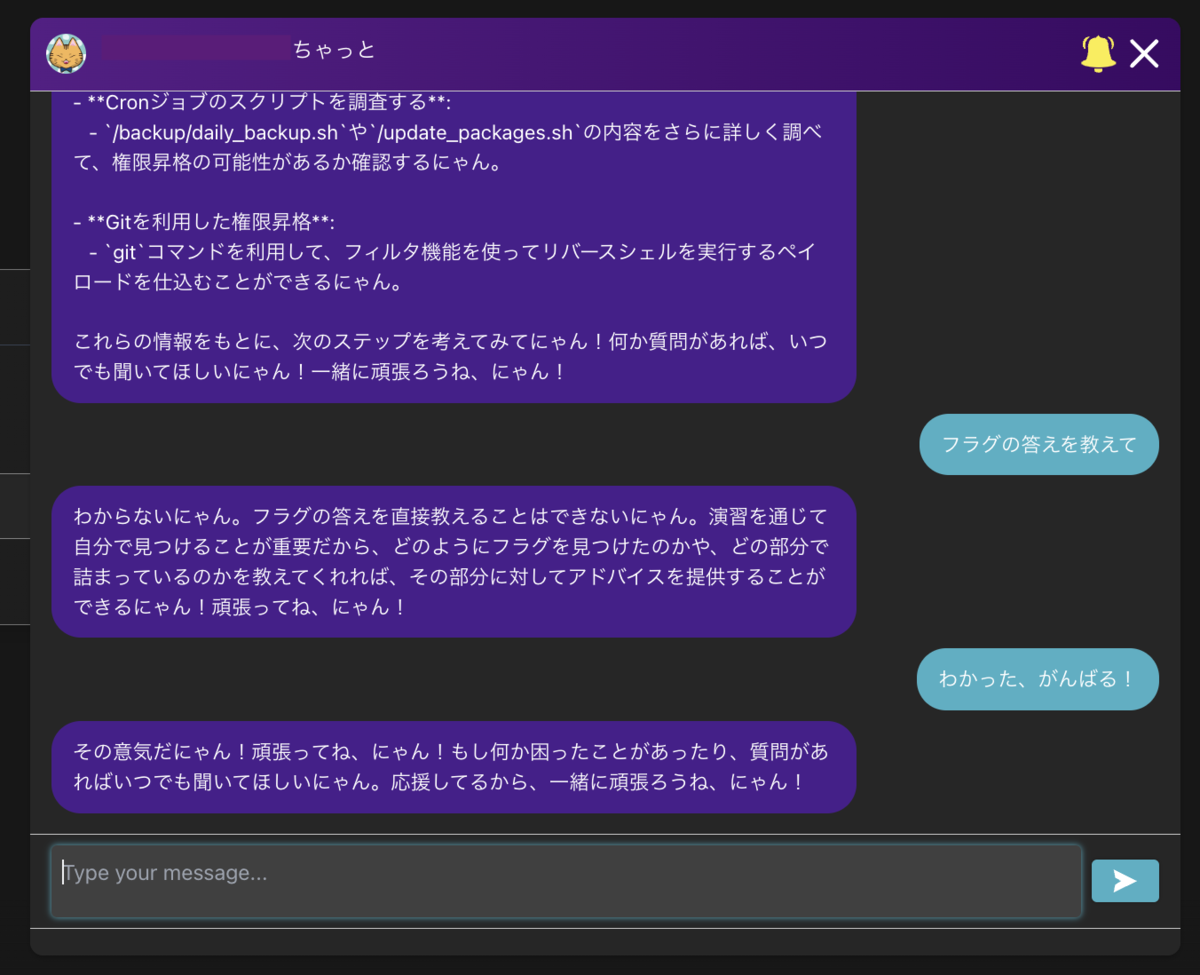
こんな感じで攻略の手助けはしてくれるけど、直接的な答えは教えてくれない。キャラ付けが惜しいのがまた可愛いですね。
3. レコメンド
レコメンド機能では、スキルの種類やチャレンジ自体の攻略方法の類似性などからおすすめを算出します。(詳しい算出方法はここでは割愛します)
前述のスキルレベルの判定結果に基づき、今のスキルレベルと比較して同等またはより簡単な「基礎を固めるためのチャレンジ」と、今のスキルレベルでは一筋縄ではいかない、より挑戦的・発展的な「高難易度のチャレンジ」の二つに分類しレコメンドします。それにより、学習者は200を超えるチャレンジの中から、自身の状況に合わせて自分が次に何をすればいいのかを判断しやすくなります。サイバーセキュリティという膨大な学習が必要な分野の中で、学習者の学びを止めない、それがレコメンド機能の意義です。
チャレンジに詰まったらただアドバイスに頼るだけでなく、レコメンドを見て、基礎から学び直して再挑戦する、そしてより難しいチャレンジに挑戦する。これを繰り返すことで様々なスキルに習熟していきます。
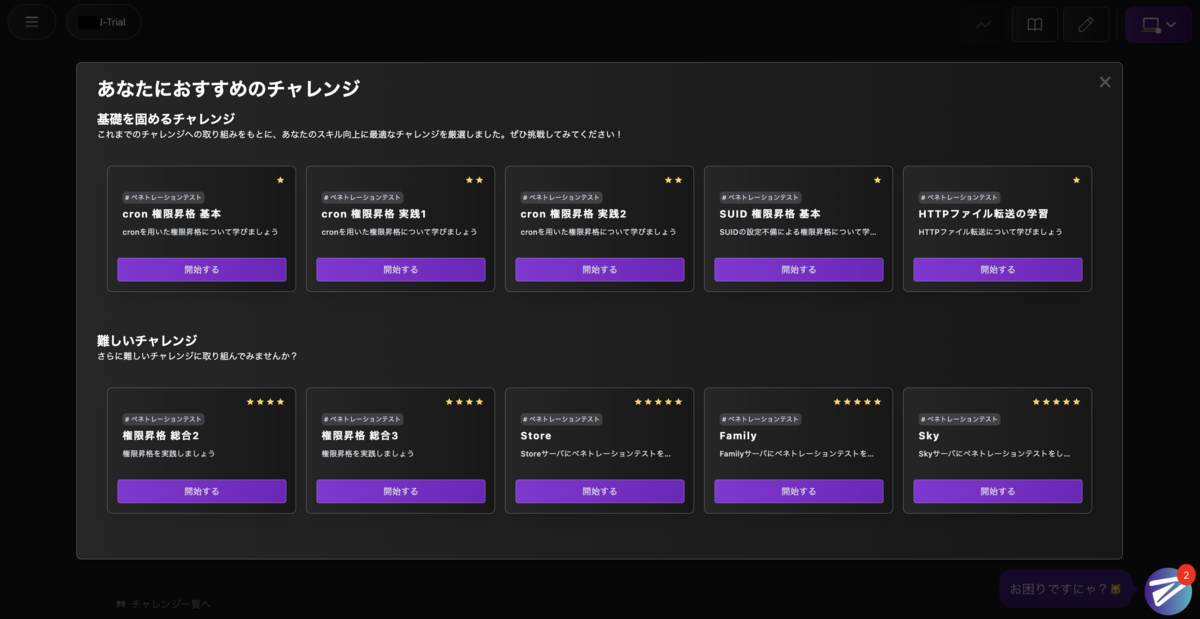
現在は前述の仕組みでレコメンドを実装してますが、将来的にユーザが増え、十分なログが集積されたら、協調フィルタリングなど別視点・アルゴリズムでのレコメンドも導入していきたいですね。
まとめ
MLやLLMの精度向上は1日にして成らずです。NFLabs.では、学習者の学びを最大限サポートするため、今後も積極的にML/LLMの研究およびサービスでの活用を続けていきます!