この記事は、NFLaboratories Advent Calendar 2022 4日目の記事です。
こんにちは、ソリューション事業部セキュリティソリューション担当の大沢です。
前回、NFLabs. エンジニアブログに『OpenCTIの日本語化にあたって』というタイトルで脅威インテリジェンスプラットフォームOpenCTIの話をさせていただきました。
今回はそのOpenCTIの検証中に検証サーバーをスクラップにした話をしようと思います。
教訓、あるいは TL;DR
- 『本番環境でやらかしちゃった人 Advent Calendar』を読もう!
- 作業前のスナップショット作成は大事
- Redisは自身のデータ領域以下のファイル・ディレクトリの所有者を全て
UID=999に変えてしまう
ことの始まり
OpenCTIは以下のリポジトリを git clone し、READMEに従って変数などを設定した後に docker compose up を実行するだけで簡単に環境を立てることができます。
我々のチームでもこの方法で検証用OpenCTIを起動し、様々な検証や開発を行っていました。
この環境は開発メンバーで機能検証するのと合わせてエンドユーザーにもフロントを公開し、業務フローの検証に使ってもらっていました。
さて、様々な情報ソースからデータを収集しながら数ヶ月運用すると次第に性能が悪化していきます。
OpenCTIは画像のような構成で動作しており、我々の環境で主に性能を悪化させていたのが Elasticsearch , Redis, RabbitMQ の3つでした。
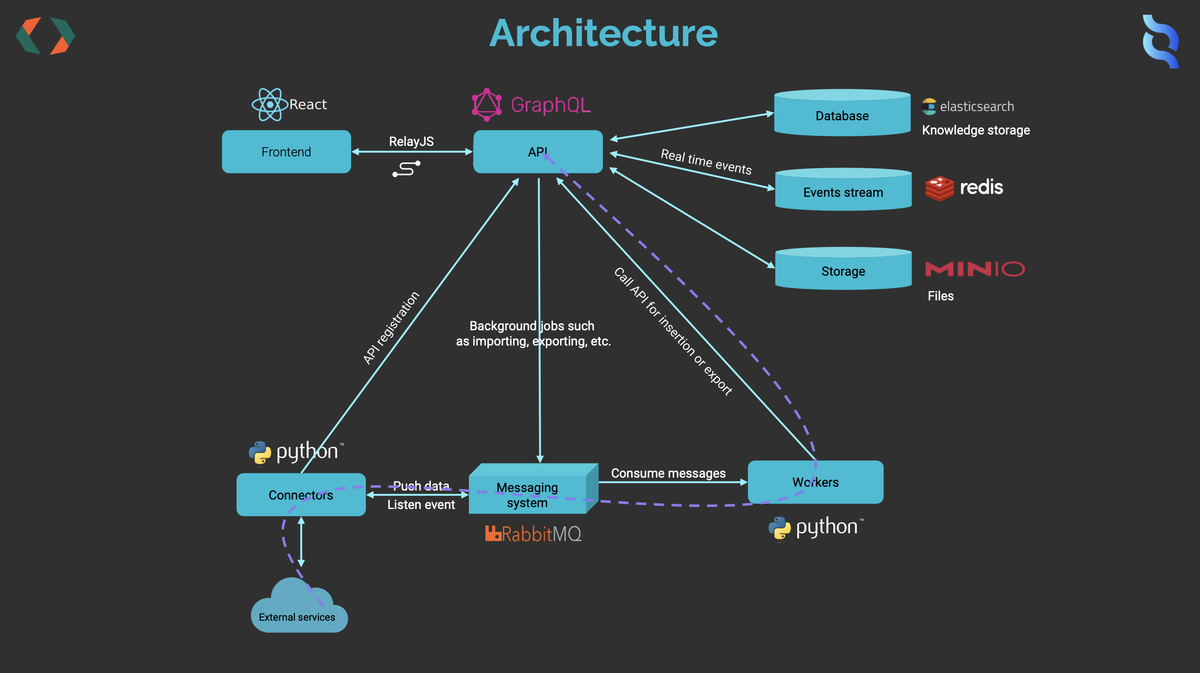
それぞれ
- Elasticsearch
- メモリの使用量が非常に大きい
- Redis
- デフォルトでキャッシュサイズに制限がない
- RabbitMQ
- デフォルトでキューの深さやデータサイズに制限がない
- 再起動すると既存のキューの内容がディスクに残ったまま新しいキューを作成する
といった感じだったので、パラメータを調べながらパフォーマンス・チューニングをおこなうことにしました。
(実際のチューニングの内容は本題とズレてしまうので割愛します)
事件発覚
さて、各コンポーネントの設定ファイルや起動オプションについて調べつつ調整をしていた時のことです。
私「あれ、sudoできないな・・・」

検証サーバーは突発的にroot権限で作業することを想定しており、開発メンバーはsudoコマンドをNOPASSWDで実行できるようにしていました。
なので、(エラーメッセージからもわかりますが)パスワードを間違えたとかそういったことはなく、ただただ『sudoコマンドが実行できない』という異常が発生していることになります。
まずはsudoコマンドのパーミッションを調べてみます。
![]()
確かにsudoコマンドの所有者のUIDは0ではなく、setuidも設定されていないようです。
ちなみに正常なsudoコマンドのパーミッションは↓
![]()
さらに調査をしてみると、すぐに、 / 以下の全てのファイル・ディレクトリの所有者が UID=999 に変更されていることがわかりました。
(画像はイメージです)
検証環境、復旧できません!
さて、めでたく(?)障害を引き起こしてしまったということで、まずはエンドユーザーに一報入れつつOpenCTIのコンポーネント群を停止し、サーバーの復旧を試みます。
本番環境であれば障害報告などを上げなければいけないところでしたが、利用者がいるとはいえあくまで検証環境だったので、大事にならなかったのは不幸中の幸いでした。
スナップショット・・・ない
まずはvCenterにログインしてスナップショットを確認します。
・・・が、検証サーバーのスナップショット一覧は空。
というのも、サーバー基盤の運用ポリシーとして長期間のスナップショットは保存せず、基本的には作業前後の切り戻しポイントとして作成するということになっていたのです。
当時は突発作業も多く、検証環境ということもあってスナップショットを作成せずに設定変更するのが日常でした。
データサルベージ・・・できない
次にSCPやSFTPなどを使ってElasticsearchとMinIOのデータサルベージを試みます。
OpenCTIはこの2個のコンポーネントに主要データを保存することになっているので、最低限ここだけでもサルベージできればすぐに復旧することができます。
しかし、パーミッションがおかしくなったことが原因なのかSSHの接続がうまくいかず、そもそもroot権限でシェルが起動できないため、データを保持していた docker volume のホスト先( /var/lib/docker )にアクセスする手段が無く、データサルベージもうまくいきませんでした。
最終的に復旧した手順
以下の手順でサーバーの復旧を行いました。
- 検証サーバーをセーフモードで再起動
- vCenterのWebコンソールを起動してサーバーにアクセス
- サルベージしたいデータをtar.gz形式で圧縮して保存
- セーフモード環境下では停止しているsshdを起動
- SCPでデータを退避
- 検証サーバーの再構築
- 退避したデータを展開
結局何が原因だったの?
Redis周りの設定をいじっている際に、Redisの /data のマウント先を誤って / にしていたことが原因でした。
通常であればコンテナを停止して済む話なのですが、Redisには『/data 以下のオブジェクトの所有者を UID=999 に書き換える』仕様があるらしく、その結果引き起こされた惨劇だったのです。
なお、今回の環境では UID=999 に対応するユーザーはいませんでしたが、 systemd-coredump というユーザーが UID=999 として存在している場合もあり、その場合はそのユーザーが所有者になるようです。
そんなこと、と思うかもしれませんが、Linuxには今回障害に気がつくきっかけになった sudo コマンドのように、特定のUID/GIDが設定されている、特定のパーミッションが設定されている、特定のPIDでdaemonが起動されている、といったことが前提で動作するシステムが多く存在します。
それら1つ1つに配慮しつつ書き換えられた情報を元に戻すのは現実的ではないので、基本的には再構築するしか道はないでしょう。
最後に
以上、スナップショットを作成せずにサーバーの変更作業をする、コンテナのVolumeマウントを間違える、といった使い古された失敗をしてしまった話でした。
古今東西様々な失敗談がありますが、ファイルシステム内の所有者をことごとく書き換えられた話はあまり聞いたことがなかったので、ここで供養しようと思います。
( chmod -R 600 / のようなコマンドを発行してしまった人の話を以前読んだことはありますが・・・ )
この記事が別の誰かの助けになれば幸いです。
さて、失敗談といえば、私が毎年楽しみにしている『本番環境でやらかしちゃった人 Advent Calendar』が今年も開催中です。
今年は投稿数が少ないようですが、皆様、こちらに寄稿できるような事態を引き起こさないように日々を過ごしていきましょう。
ありがとうございました。